
Bloom Filters: Your Guide to High-Performance Data Structure. Discover Why They’re a Must-Have Tool, What They Are, and How to Implement Them
Before understanding what are they let’s understand why they exist.
Let’s discuss a scenario, Suppose you’re writing a web service that allows users to upload images, and you want to check whether a newly uploaded image is a duplicate of an image that’s already in your database. What you would do? You could compare the new image to every existing image in your database, but this would be slow and inefficient, especially if your database is large. Maybe you could introduce a cache service between your app server and database to make it work a little faster. But with this, you introduced memory inefficiency as you have to store the same data in the cache.
There is a better approach to optimally solve the above problem and that is bloom filters
What it is?
Bloom Filters are a type of probabilistic data structure that’s used to test set membership in a fast and space-efficient way.
Why it is a probabilistic data structure?
When you query a key in this data structure they provide a probabilistic answer to the question of whether an element is in a set or not.

- When a query is made to a Bloom Filter and the element is not present in the set, the filter will return a
"True Negative". This means that the element definitely does not exist in the set. - However, if the query returns a positive result, it could be a
"False Positive".This means that the element may or may not exist in the dataset.
Rings any bell? you might be wondering why it is still useful in today’s world of data structures. After all, why not just use a simple hash table? Keep reading we will explore these together.
Real-life use case of bloom filters
- Google Chrome use case
Google Chrome uses a Bloom Filter to quickly check if a URL is in its blacklist of known malicious websites.

- Malware detection: Bloom filters can be used by antivirus software to quickly determine whether a file or network packet is likely to contain malware, and thus reduce the number of false negatives and false positives in malware detection.
- CDNs like Akamai use Bloom filters to quickly determine whether a requested resource is likely to be in their cache, and thus avoid expensive origin server requests for uncached content.
- Web search: Bloom filters can be used by search engines to quickly identify documents that contain a given keyword or phrase, and thus improve the efficiency of web search.
- The Cassandra distributed database uses a Bloom Filter to quickly check if a key exists
- sign-in service: Username is taken or not.
- Web crawling to keep track of visited URLs and avoid revisiting them,
How does it actually work?
a Bloom Filter is a bit array of a fixed size, initialized to all zeros. To add an element to the filter, the element is first hashed using a set of hash functions(one to many). The resulting hash values are then used to set the corresponding bits in the bit array to 1.
Preparation of data
Let’s create a bucket of size say 10 filled with 0

Now let’s create three hash functions — h1, h2, and h3 — to hash our inputs, and set the corresponding bits to 1. For example, let’s say we want to hash the inputs “red” and “blue”. We apply these hash functions to each input and then set the resultant bit indexes to 1.
So, after hashing “red” and “blue” through h1, h2, and h3, we would end up with a bit array that looks something like this:
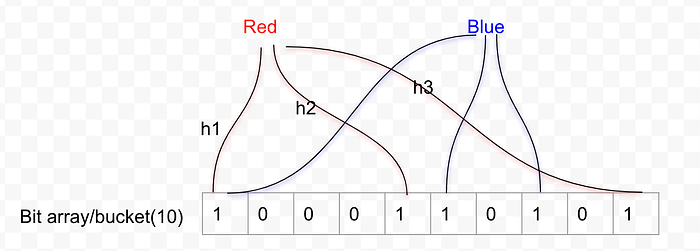
we utilize multiple hash functions when hashing input data in Bloom filters to minimize the occurrence of hash collisions and thus reduce the likelihood of false positives.
Querying of data
Now for querying the Bloom filter with a new element, we apply the same hash functions to generate the corresponding bit indexes in our bit array. If all of these bit indexes are set to 1, we say that the element “may” be in the set, because there is a chance of false positives due to the probability of hash collisions.
However, if any of the corresponding bit indexes are 0, we can say with certainty that the element is “not” in the set, as it was not added during the filter’s construction phase.
Major benefits we get using this data structure
- Space-efficient: As it does not store all the data
- Fast querying: Bloom filters can quickly determine whether an element is “likely” to be in the set or definitely not in the set
There is a trade-off between memory usage and less accuracy. Since memory usage carries more weight, it makes Bloom filters a better choice than hash tables. Unlike hash tables, which must write all of the data into storage, Bloom filters can perform searches with much lower costs. In situations like searching for a key in a large database such as Cassandra, Bloom filters can be incredibly useful.
Thank you for reading this article on Bloom filters. I hope you found it informative and engaging. Stay tuned for my upcoming article on implementing Bloom filters in Python. Don’t forget to subscribe to stay updated on the latest articles.
